- cpp/
3. 内存管理
Table of Contents
内存对齐#
对齐:计算机中内存空间都按照 byte 划分,理论上似乎对任何类型的变量的访问可以从任何地址开始;但实际在访问特定类型变量时,需要各种类型数据按照一定规则在特定空间上排列,而不是顺序地、紧连着排放
#include <stdint.h> struct { uint32_t m1; char m2; } varray; int main() { printf("%d\n",sizeof(varray.m1)); // 输出4 printf("%d\n",sizeof(varray.m2)); // 输出1 printf("%d\n",sizeof(varray)); // 输出8 return 0; }
内存对齐原因#
平台原因(移植原因)
不是所有的硬件平台都能访问任意地址上的任意数据的
某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常
性能原因
数据结构(尤其是栈)应该尽可能地在自然边界上对齐
为了访问未对齐的内存,处理器需要作两次内存访问;而对齐的内存访问仅需要一次访问
内存对齐规则#
- 不同平台的编译器都有自己的默认“对齐系数”(对齐模数)
- 通过预编译命令
#pragma pack(n)(n=1,2,4,8,16),其中 n 就是指定的“对齐系数” - 有效对齐值:
#pragma pack指定值 和 结构体中最长数据类型长度 中较小的值,也叫对齐单位 - 具体规则:
- 结构体变量的首地址是有效对齐值(对齐单位)的整数倍
- 结构体第一个成员的偏移量(offset)为0,以后每个成员相对于结构体首地址的 offset 都是该成员大小与有效对齐值中较小数值的整数倍,如有需要编译器会在成员间填充字节
- 结构体的总大小为 有效对齐值 的整数倍,如有需要编译器会在最末一个成员后填充字节
- 结构体内类型相同的连续元素将在连续的空间内,就像数组一样
- 按照元素声明的顺序分配内存
#pragma pack(n)#
设定结构体、联合以及类成员变量以 n 字节方式对齐
原理:通过改变有效对齐值来改变数据成员在内存中的布局,如果设定的 n 值没有影响或改变有效对齐值,则成员的内存布局不变
使用:
#pragma pack(push) // 保存对齐状态 #pragma pack(4) // 设定为 4 字节对齐 struct test { char m1; double m4; int m3; }; #pragma pack(pop) // 恢复对齐状态注意:
- VS、VC 默认是#pragma pack(8)
- gcc 默认是#pragma pack(4),且gcc只支持1, 2, 4对齐
POD(Plain Old Data)数据#
- 特征:
- 不能写构造/析构函数、拷贝/移动构造函数、拷贝/移动运算符,而是用编译器自动生成的
- 布局有序:
- 所有非静态成员有相同的访问权限,比如都是private的,或者都是public,或者都是protected
- 继承树中最多只能有一个类有非静态数据成员(在类或结构体的继承时,满足以下两种情况之一:① 派生类中有非静态成员,且只有仅包含静态成员的基类 ② 基类有非静态成员,而派生类没有非静态成员)
- 类中第一个非静态成员的类型与其基类不同
- 没有虚函数和虚基类
- 所有非静态成员都符合标准布局类型,其父类也符合标准布局
- 可直接使用
memcpy等函数 - C++判断:
is_pod<T>::value
结构体成员偏移量#
实现
struct node_t { char a; int b; int c; }; struct node_t node; // 方法1 (unsigned long)(&(node.c)) - (unsigned long)(&(node)) // 方法2 #define OFFSET_OF(type, member) (unsigned long)(&(((type *)0)->member))
大小端检测方法#
- 大端模式:数据的高字节在内存的低地址,低字节在内存的高地址端
- 小端模式:数据的高字节在内存的高地址,低字节在内存的低地址端
- Linux C中判断cpu大小端序的几种方法: 用指针判断linux中是大端还是小端
Linux内核对大小端处理#
static union { char c[4]; unsigned long mylong; } endian_test = {{ 'l', '?', '?', 'b' } }; #define ENDIANNESS ((char)endian_test.mylong) // 如果ENDIANNESS=‘l’则代表是小端 .是'b'则代表是大端. if (ENDIANNESS == 'b')/* 高位在低字节 */ printf("大端序\n"); else printf("小端序\n");使用联合体#
int check_cpu_type(){ union w { int a; char b; } c; c.a = 1; if (c.b == 1)/* 低位低字节 */ printf("小端序\n"); else printf("大端序\n"); }使用指针#
int check_cpu_type() { int i = 0x1; unsigned char *p; p = (unsigned char *)&i; if (*p) printf("小端序\n"); else printf("大端序\n"); }
程序在内存中的分段#
当一个程序运行时,程序的不同部分会在不同区域的内存中存储
代码段/正文段:由CPU执行的机器指令部分
- 由装载器装载,将可执行文件读取或映射到该内存,程序如何运行由代码段决定
- 代码段的内容是只读的,以防止程序由于意外而修改其指令
- 代码段是可以共享的;一个程序的可以同时执行
N次,但该程序的代码段在内存中只需要存在一份
只读段:用来存储只读数据的
- 存放常量字符串,字面值数据,常量等
- 程序运行结束时由内核自动释放
数据段/初始化数据段/
DATA段:存储初始化过的全局变量、静态变量- 在程序开始执行之前,内核将此段中的变量初始化为程序赋予的初值
- 程序运行结束时由内核自动释放
静态数据段/未初始化数据段/
BSS段:存储未初始化过的全局变量、静态变量- 在程序开始执行之前,内核将此段中的数据初始化为0或者空指针
- 程序运行结束时由内核自动释放
数据段 和 静态数据段 又统称为 全局(静态)存储区
栈 (stack):存储局部变量、块变量等数据
- 由内核管理、自动分配和释放,存放函数调用过程中的各种参数、局部变量、返回值以及函数返回地址
- 操作方式类似数据结构中的栈
堆 (heap):由程序管理的一块内存
- 由程序自身动态申请分配和释放空间
- C语言中的 malloc 和 free
- C++中的 new 和 delete
- 正常情况下,程序申请的空间在使用结束后需要释放;若程序没有释放,则程序结束时内核自动回收
栈 (stack)#
申请/释放方式:由内核自动分配、释放
void func () { int b; // 声明时由内核自动申请分配 /* do something */ }; // 函数退出时由内核自动释放申请后内核的响应:只要栈的剩余空间大于申请空间,内核将为程序提供内存,否则将报异常提示栈溢出
申请大小的限制:
- Windows下栈是向低地址扩展的数据结构,是一块连续的内存的区域
- 栈顶的地址和栈的最大容量是内核预先规定好的常量,一般的WINDOWS栈的大小是2M或1M
申请效率:栈由内核自动分配,速度较快
栈的存储内容:
主函数中后的下一条指令(函数调用语句的下一条可执行语句)的地址,以及调用者的环境信息(如某些CPU 寄存器的值)
函数的各个参数(在大多数的C编译器中,参数是由右往左入栈的)
函数中的局部变量
函数调用的顺序依次是指令地址等、函数参数、函数局部变量
当函数调用结束后,出栈顺序为函数局部变量、函数参数,最后栈顶指针指向最开始存的地址,也就是主函数中的下一条指令,程序由该点继续运行
特点:
- 栈是线程独有的,即栈是线程安全的
- 栈内存的大小有限,不适合保存大量数据
- 栈内存不适合长久保存数据(当函数结束后它就会被释放)
堆 (heap) & 内存分配和管理#
C/C++堆内存相关方法#
| 分配 | 释放 | 类型 | 是否重新定义 |
|---|---|---|---|
| malloc() | free() | C函数 | 不可 |
| new | delete | C++表达式 | 不可 |
| ::operator new() | ::operator delete() | C++函数 | 可以,重载 |
| allocator | allocator | C++标准库 | 可自由设计并搭配任何容器 |
malloc/calloc/realloc/alloca#
malloc:申请指定字节数的内存。申请到的内存中的初始值不确定。
原理:
i. 空闲链表:将可用的内存块连接为一个长链表
ii. 调用malloc函数时,沿链表寻找一块满足需要大小的内存
iii. 将该内存块一分为二,一块的大小为所需内存大小,另一块的是剩下的内存空间
iv. 将分配给用户的内存传给用户,并将剩下的(如果有的话)返回到连接表上
v. 调用free函数时,将用户释放的内存块连接到空闲链上
vi. 如果空闲链会被切成很多的小内存片段,空闲链上可能不能满足用户要求的片段。则malloc函数请求延时,并开始在空闲链上检查各内存片段并整理,将相邻的小空闲块合并成较大的内存块。
vii. 如果还无法获得符合要求的内存块,malloc函数会返回NULL指针,因此在调用malloc动态申请内存块时,一定要判断返回值
calloc:为指定长度的对象,分配能容纳其指定个数的内存。申请到的内存的每一位(bit)都初始化为 0。
realloc:更改以前分配的内存长度(增加或减少)。当增加长度时,可能需将以前分配区的内容移到另一个足够大的区域,而新增区域内的初始值则不确定。
alloca:在栈上申请内存。程序在出栈的时候,会自动释放内存。但是需要注意的是,alloca 不具可移植性, 而且在没有传统堆栈的机器上很难实现。alloca 不宜使用在必须广泛移植的程序中。C99 中支持变长数组 (VLA),可以用来替代 alloca。(Google风格不允许使用)
malloc & free#
malloc:申请内存,需要确认是否申请成功
char *str = (char*) malloc(100); assert(str != nullptr);free:释放由
malloc申请的内存,释放内存后指针需要置空,否则造成野指针/无效指针free(p); p = nullptr;
new & delete#
new / new[]:完成两件事,先底层调用 malloc 分配了内存,然后调用构造函数(创建对象)。
delete/delete[]:也完成两件事,先调用析构函数(清理资源),然后底层调用 free 释放空间。
new 在申请内存时会自动计算所需字节数,而 malloc 则需我们自己输入申请内存空间的字节数。
new 必须和 delete 配合使用
new 申请的内存在堆中,不会随着函数结束而消失
new & delete 使用:
int main() { T* t = new T(); // 先内存分配 ,再构造函数 delete t; // 先析构函数,再内存释放 return 0; }new 的实现细节: new 先通过
malloc分配内存,再调用构造函数Complex* pc = new Complex(1,2); // new expression(new表达式)编译器转换为:
Complex* pc; try { void mem = operator new( sizeof(Complex) ); // 全局函数或者重载的函数;分配内存,内部调用malloc pc = static_cast<Complex*>(mem); pc->Complex::Complex(1,2); // 编译器调用构造函数,GCC中只有编译器才能这样调用 new(pc)Complex::Complex(1,2); // 或采用定位new直接,等于直接调用构造函数 } catch (std::bad_alloc){ ... }delete 的实现细节: delete 先调用析构函数,再通过
free释放内存delete pc; // delete expression编译器转换为:
pc->~Complex(); // 析构函数 operator delete(pc); // 全局函数或者重载的函数;清理内存,内部调用free
new/delete 内存分配途径
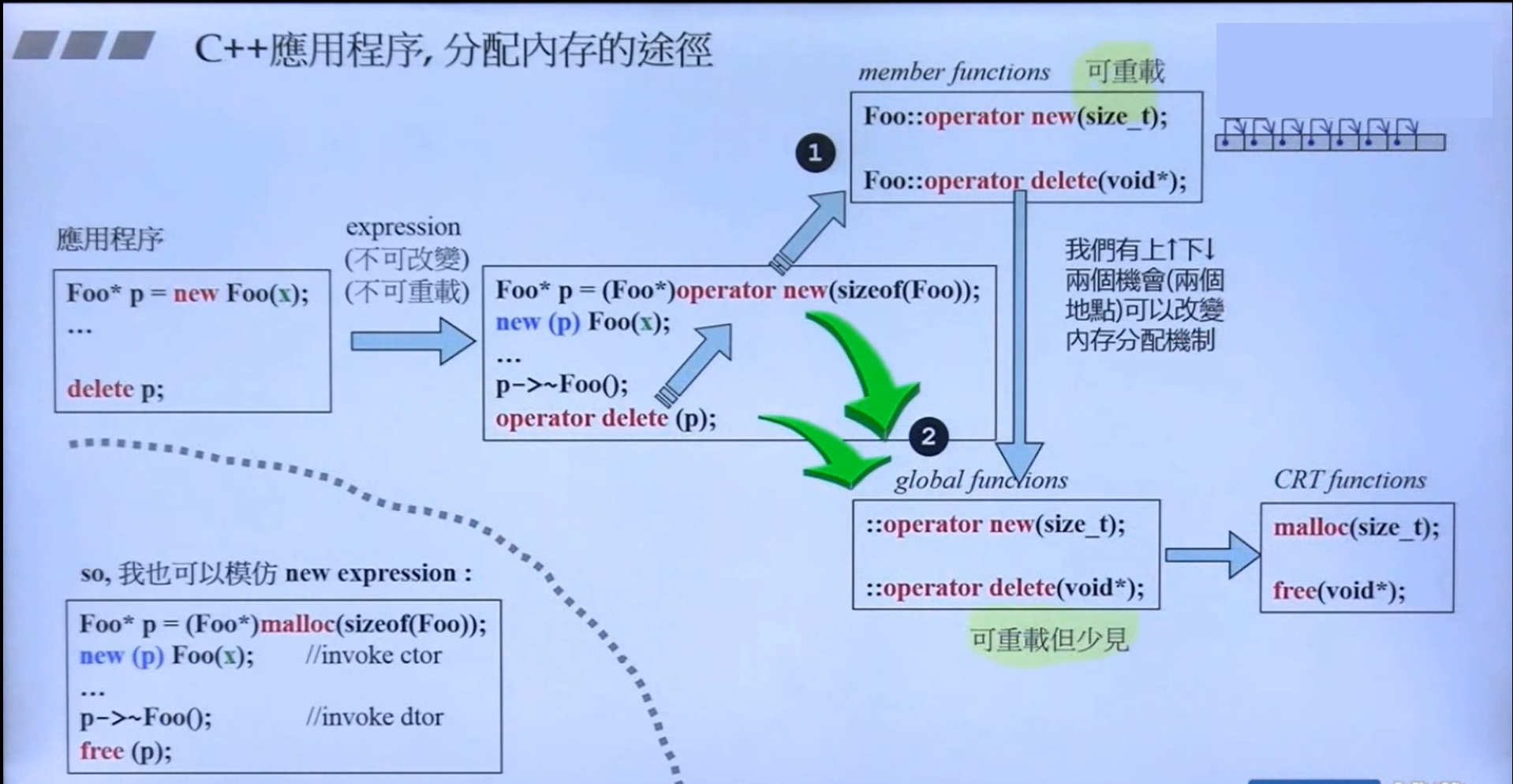
定位 new (placement new)#
在用户指定的已经分配的内存上构建对象,但不会申请新的内存,只会调用对象的构造函数;同时允许向 new 传递额外的地址参数,从而在预先指定的内存区域创建对象。
new (place_address) type
new (place_address) type (initializers)
new (place_address) type [size]
new (place_address) type [size] { braced initializer list }
place_address是个指针initializers提供一个(可能为空的)以逗号分隔的初始值列表SGI STL 3.0版本的里面的源代码:
// vector已经2个元素,而实际内存是4个的 // 再向vector中push一个元素,因为vector还有2个未用的空间,所以不需要申请内存 // 只需要在原来已经分配好的内存中调用元素的构造函数 template <class T1, class T2> inline void construct(T1* p, const T2& value) { new (p) T1(value); } // vector push_back函数 void push_back(const T& x) { if (finish != end_of_storage) { construct(finish, x); ++finish; } else insert_aux(end(), x); }placement delete:如果一个带额外参数的operator new (即placement new) 没有“带相同参数”的对应版operator delete,那么就当new的内存分配动作出现异常时就没有任何operator delete被调用,于是产生内存泄露。
重载 operator new / delete#
- 重载规则
- new和delete运算符重载必须成对出现
- new运算符的第一个参数必须是
size_t类型,delete运算符的第一个参数则必须是要销毁释放的内存对象 - 内核默认实现了
new/delete、new[]/delete[]、placement new/delete6个运算符函数 - 当delete运算符的参数 ≥ 2时,需要自己调用析构函数,并且以运算符函数的形式来调用delete运算符
示例:
class A { public; A(){} void *operator new(size_t size); void *operator new[](size_t size); void *operator new(size_t size, void *p); // placement new void *operator new(size_t size, int a, int b); void operator delete(void *p); void operator delete[](void *p); // placement delete,只有placement new不能完整执行时调用 void operator delete(void *p, void *p1); void operator delete(void *p, int a, int b); }; class B { public: B(){} }; //全局运算符函数,请谨慎重写覆盖全局运算符函数。 void *operator new(size_t size); void *operator new[](size_t size); void *operator new(size_t size, void *p) noexcept; void *operator new(size_t size, int a, int b); void operator delete(void *p); void operator delete[](void *p); void operator delete(void *p, void *p1); void operator delete(void *p, int a, int b); int main() { char buf[100]; A *a1 = new CA(); //调用void * A::operator new(size_t size) A *a2 = new CA[10]; //调用void * A::operator new[](size_t size) A *a3 = new(buf)CA(); //调用void * A::operator new(size_t size, void *p) A *a4 = new(10, 20)CA(); //调用void* A::operator new(size_t size, int a, int b) delete a1; //调用void A::operator delete(void *p) delete[] a2; //调用void A::operator delete[](void *p) a3->~CA(); //a3用的是placement new的方式分配,因此需要自己调用对象的析构函数。 A::operator delete(a3, buf); //调用void CA::operator delete(void *p, void *p1),要带上类命名空间 a4->~CA(); //a4的运算符参数大于等于2个,所以需要自己调用对象的析构函数 A::operator delete(a4, 10, 20); //调用void CA::operator delete(void *p, int a, int b) //B类没有重载运算符,因此使用的是全局重载的运算符。 B *b1 = new B(); //调用void * operator new(size_t size) B *b2 = new B[10]; //调用void * operator new[](size_t size) //这里你可以看到同一块内存可以用来构建CA类的对象也可以用来构建CB类的对象 B *b3 = new(buf)B(); //调用void * operator new(size_t size, void *p) B *b4 = new(10, 20)CB(); //调用void* operator new(size_t size, int a, int b) delete b1; //调用void operator delete(void *p) delete[] b2; //调用void operator delete[](void *p) //b3用的是placement new的方式分配,因此需要自己调用对象的析构函数。 b3->~B(); ::operator delete(b3, buf); //调用void operator delete(void *p, void *p1) //b4的运算符参数大于等于2个所以需要自己调用对象的析构函数。 b4->~B(); ::operator delete(b4, 10, 20); //调用void operator delete(void *p, int a, int b) return 0; }
如何定义只能在堆/栈生成对象的类?#
c++ - how to create object on 1>stack only and not on heap and 2>heap only not on stack
| 只能在堆上 | 只能在栈上 | |
|---|---|---|
| 方法 | 将析构函数设置为私有 | 将 new 和 delete 重载为私有 |
| 原理 | C++编译器委托内核管理栈上对象的生命周期,分配空间前会先检查类的析构函数的访问性。若析构函数不可访问,则不能在栈上创建对象。 | 将 new 设置为私有,无法在堆上寻找可用内存并分配给对象,就不能够在堆上生成对象。 |
delete this 合法吗?#
Is it legal (and moral) for a member function to say delete this?
合法,但:
- 必须保证 this 对象是通过
new(不是new[]、不是 placement new、不是栈上、不是全局、不是其他对象成员)分配的 - 必须保证调用
delete this的成员函数是最后一个调用 this 的成员函数 - 必须保证成员函数的
delete this后面没有调用 this 了 - 必须保证
delete this后没有人使用了
共享内存 (Shared Memory)#
何谓共享内存#
共享内存:在多处理器的计算机系统中,共享内存能够被不同CPU访问的大容量内存,或多个进程共享的一块内存存储区域
特点:
进程间传递数据速度最快的一种方式,共享内存生命周期随内核
共享内存没有自带同步或互斥,由用户来维护共享内存(一般使用信号量来同步对共享内存的访问)
操作概览:
SYSTEM V POSIX 分配 shmget() shm_open() 映射 shmat() mmap() 卸载 shmdt() munmap() 删除/释放 - shm_unlink() 控制 shmctl() ftruncate() System V 共享内存和共享文件映射的缺点:
i. System V 共享内存模型使用的是键和标识符,与标准的 UNIX I/O 模型使用文件名和描述符不一致,意味着使用 System V 共享内存需要一整套全新的系统调用和命令
ii. 使用一个共享文件映射进行 IPC 要求创建一个磁盘文件,即使无需对共享区域进行持久存储也需要,创建文件的方式带来不便之处,也带来一些文件 I/O 开销
SYSTEM V 标准接口#
shmget()
#include <sys/ipc.h> #include <sys/shm.h> //如果共享内存不存在,创建共享内存,如果存在就打开共享内存 int shmget(key_t key, size_t size, int shmflg); //返回值:成功返回共享内存的标识符,失败返回-1参数 说明 key 共享内存的标识符,也可当做共享内存的名字,可由 ftok获取size 共享内存大小,一般指定为4k的倍数(内存4k为一页) shmflg 共享内存的访问权限
IPC_CREAT:创建新的共享内存
IPC_EXCL:与IPC_CREAT一同使用,如共享内存已经存在,则返回错误
IPC_NOWAIT:读写共享内存要求无法满足时,不阻塞
0:如打开已存在文件,则写0shmat()
#include <sys/types.h> #include <sys/shm.h> //将共享内存链接到进程地址空间 void *shmat(int shmid, const void *shmaddr, int shmflg); //返回值:失败返回NULL // 成功返回地址指针,且连接数加1(nattch)参数 说明 shmid 表示符shmid,shmget的返回值 shmaddr 指定连接进程地址空间的地址
0:由内核映射的第一个可用地址上(推荐方式)
非0且shmflg不是SHM_RND:映射到addr所指定的地址上
非0且shmflg是SHM_RND:映射到(shmaddr -(shmaddr % SHMLBA))所表示的地址上(SHMLBA是低边界地址倍数,总是2的乘方)shmflg 共享内存的权限
SHM_RND:配合shmaddr使用,意味取整
SHM_RDONLY:只读共享内存shmdt()
#include <sys/types.h> #include <sys/shm.h> //将共享内存与当前连接进程脱离 int shmdt(const void* shmaddr) //返回值:成功返回0,失败返回-1 //注意:将共享内存与进程脱离不等于删除共享内存参数 说明 shmaddr 由shmat返回的指针 shmctl()
#include <sys/ipc.h> #include <sys/shm.h> //shmctl系统调用对shmid标识的共享内存执行cmd操作 int shmctl(int shmid, int cmd, struct shmid_ds *buf); //返回值:成功返回0,失败返回-1参数 说明 shmid 表示符shmid,shmget的返回值 cmd IPC_STAT:把shmid_ds结构中的数据设置为共享内存的当前关联值
IPC_SET:如进程权限满足,将当前关联值设置为shmid_ds结构中的数值
IPC_RMID:删除共享内存buf struct shmid_ds定义在<sys/shm.h>中使用示例:
#include <stdio.h> #include <stdlib.h> #include <sys/ipc.h> #include <sys/shm.h> #include <string.h> #define SHM_SIZE 1024 // 共享内存大小 int main() { int shmid; char *shmaddr; char sharedMemReadBuf[1024] = {0}; key_t key = ftok(".", 's'); // 获取共享内存标识符 if (key == -1) { perror("ftok"); exit(1); } // 创建共享内存区域 shmid = shmget(key, SHM_SIZE, IPC_CREAT | IPC_EXCL); if (shmid == -1) { perror("shmget"); exit(1); } // 将共享内存映射到进程地址空间中 shmaddr = shmat(shmid, NULL, 0); if (shmaddr == (char *) -1) { perror("shmat"); exit(1); } #if 1 // 在共享内存中写入数据 strncpy(shmaddr, "Hello, SYSTEM-V shared mem!", SHM_SIZE); #else // 读数据 // memcpy(sharedMemReadBuf, shmaddr, 1024); // printf("sharedMemReadBuf:%s\n", sharedMemReadBuf); #endif // 卸载共享内存 if (shmdt(shmaddr) == -1) { perror("shmdt"); exit(1); } return 0; }
POSIX标准接口#
shm_open()
#include <sys/mman.h> #include <sys/stat.h> /* For mode constants */ #include <fcntl.h> /* For O_* constants */ int shm_open(const chart *name, int oflag, mode_t mode); //返回值:成功返回文件描述符fd,失败返回-1参数 说明 name 待创建或待打开的共享内存对象 oflag 改变调用行为的位掩码
O_CREAT:不存在则创建对象,新的共享内存对象初始长度为 0,其大小由 ftruncate 调整
O_EXCL:与 O_CREAT 互斥地创建对象,如 O_CREAT 指定名字的共享内存对象已存在,则返回错误
O_RDONLY:打开只读访问
O_RDWR:打开读写访问
O_TRUNC:将对象长度截断为零mode 设置对象权限的掩码值(与open() 系统调用类似),在不创建新对象时指定为 0 mmap()
#include <sys/mman.h> void *mmap(void *addr, size_t len, int prot, int flags, int fd, off_t off); //返回值:成功返回映射的内存地址指针,失败返回NULL参数 说明 addr 将文件映射到的内存地址,一般传递NULL由内核指定 len 映射文件的数据长度 prot 内存区域的操作权限(保护属性)
PROT_READ
PROT_WRITEflags 标志位参数
MAP_SHARED:建立共享用于进程间通信,不同进程读取到同一份数据
MAP_PRIVATE:只有进程自己用的内存区域
MAP_ANONYMOUS:匿名映射区fd 文件描述符,用 shm_open打开或者open打开的文件 off 映射文件相对于文件头的偏移位置 munmap()
#include <sys/mman.h> int munmap(void *addr, size_t len); //返回值:成功返回0,失败返回-1参数 说明 addr 由mmap成功返回的地址 len 卸载的内存长度 注意:munmap 只是将映射的内存从进程的地址空间卸载/撤销,如进程终止前不调用,则该内存将不被释放
shm_unlink()
#include <sys/mman.h> #include <sys/stat.h> /* For mode constants */ #include <fcntl.h> /* For O_* constants */ int shm_unlink(const char *name); //返回值:成功返回文件描述符fd,失败返回-1参数 说明 name 需要删除的共享内存对象 注意:所有进程都卸载(unmap)某块共享内存后,内核将清除内存内容
ftruncate()
#include <unistd.h> int ftruncate(int fd, off_t length); //返回值:成功返回0,失败返回-1参数 说明 fd 文件描述符,且要求写权限 length 调整后的大小 注意:任何open打开的文件都可用,不限于shm_open打开的文件
使用示例:
#include <stdio.h> #include <stdlib.h> #include <fcntl.h> #include <sys/mman.h> #include <unistd.h> #include <string.h> #define SHM_SIZE 1024 // 共享内存大小 #define SHM_NAME "/myshm" // 共享内存名称 int main() { int fd; char *shmaddr; char sharedMemReadBuf[1024] = {0}; const char *msg = "Hi, POSIX shared mem!"; // 创建共享内存区域 fd = shm_open(SHM_NAME, O_CREAT | O_RDWR, 0666); if (fd == -1) { perror("shm_open"); exit(1); } // 调整共享内存区域的大小 if (ftruncate(fd, SHM_SIZE) == -1) { perror("ftruncate"); exit(1); } // 映射共享内存区域到进程地址空间中 shmaddr = mmap(NULL, SHM_SIZE, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0); if (shmaddr == MAP_FAILED) { perror("mmap"); exit(1); } #if 1 // 在共享内存中写入数据 strncpy(shmaddr, msg, SHM_SIZE); #else // 读数据 // memcpy(sharedMemReadBuf, shmaddr, 1024); // printf("sharedMemReadBuf:%s\n", sharedMemReadBuf); #endif // 卸载共享内存区域与进程地址空间的映射关系 if (munmap(shmaddr, SHM_SIZE) == -1) { perror("munmap"); exit(1); } // 删除共享内存区域的文件名并释放资源 if (shm_unlink(SHM_NAME) == -1) { perror("shm_unlink"); exit(1); } return 0; }
零拷贝 (Zero-Copy)#
何谓零拷贝#
零拷贝:在计算机执行操作时,CPU无需先将数据从某处内存复制到另一个特定区域
优点:减少用户态与内核态之间切换的次数,减少CPU用户拷贝数据的时间片占用,提升程序性能
主要类别:
- 磁盘文件零拷贝
- 网络数据零拷贝
硬件支持#
- DMA
- 直接内存访问 (Direct Memory Access, DMA) 作为一种内存访问技术,允许某些计算机内部的硬件子系统(即计算机外设),能够独立地直接读写系统内存,而无需CPU介入处理
- 在同等程度的CPU负担下,DMA是一种快速的数据传送方式
- 支持DMA的硬件有网卡、声卡、显卡、磁盘控制器等
- 零拷贝中的作用:数据直接由硬件到内存的复制
- MMU
- 内存管理单元 (Memory Management Unit, MMU),或称分页内存管理单元 (Paged Memory Management Unit, PMMU),是一种负责处理CPU的内存访问请求的计算机硬件
- 功能有虚拟地址到物理地址的转换 (即虚拟内存管理)、内存保护、CPU高速缓存 (Cache) 的控制
- 零拷贝中的作用:内存的映射,即进程“看得到”内存
非零拷贝实现#
以将磁盘文件内容通过网络发出为例
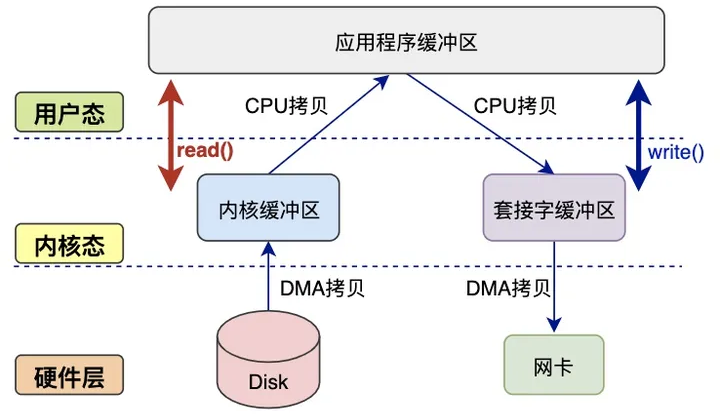
读数据过程:
- 程序读取磁盘文件,调用
read(),用户态切换内核态 - DMA将文件由磁盘拷贝到内核缓冲区,进行1次DMA拷贝
- CPU将数据从内核缓冲区复制到用户缓冲区,进行1次CPU拷贝
- CPU完成拷贝后,
read()函数返回,内核态切换用户态
- 程序读取磁盘文件,调用
写数据过程:
- 程序向网卡写数据,调用
write()函数,用户态切换内核态 - CPU将用户缓冲区数据拷贝到内核缓冲区,进行1次CPU拷贝
- DMA将数据从内核缓冲区复制到
socket缓冲区,进行1次DMA拷贝 write()函数返回,内核态切换用户态
- 程序向网卡写数据,调用
性能开销:
- 读过程有2次内核态-用户态切换、1次DMA拷贝、1次CPU拷贝
- 写过程有2次内核态-用户态切换、1次DMA拷贝、1次CPU拷贝
缺点:
- 涉及到多次内核态-用户态切换,陷入内核性能开销大
- 存在多次CPU数据拷贝,CPU负担加重
零拷贝实现#
mmap#
实现方式:
mmap参考 POSIX共享内存,可直接映射内核缓冲区到用户态缓冲区,实现内核态与用户态缓冲区的共享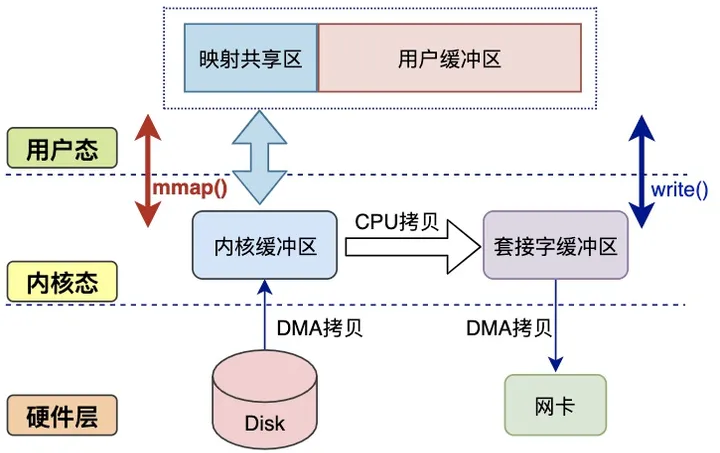
优点:
- 减少内核态-用户态切换,以及用户态-内核态之间的CPU拷贝
mmap对大文件操作、传输存在一定优势
缺点:
- 内核态内部仍然存在CPU拷贝
mmap处理小文件可能出现碎片- 多个进程同时操作文件时可能产生引发
coredump,即无资源竞争的安全性保障
sendfile#
实现方式:
sendfile系统调用由 Linux内核2.1版本引入,建立了两个文件间的传输通道,完成read+write或mmap+write功能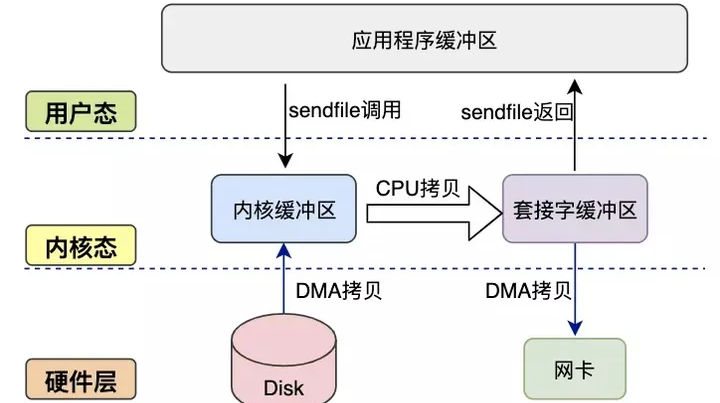
优点:
- 减少内核态-用户态切换
缺点:
- 由于数据不经过用户缓冲区,因此该数据无法被程序修改
sendfile在内核态内部仍存在CPU拷贝
sendfile+DMA#
实现方式:
- Linux 内核2.4版本优化了
sendfile系统调用,但需硬件DMA的配合 sendfile将内核缓冲区中的文件描述符fd、地址偏移量等描述性信息记录到socket缓冲区中- DMA根据
socket缓冲区中的信息将数据从内核缓冲区直接拷贝到网卡
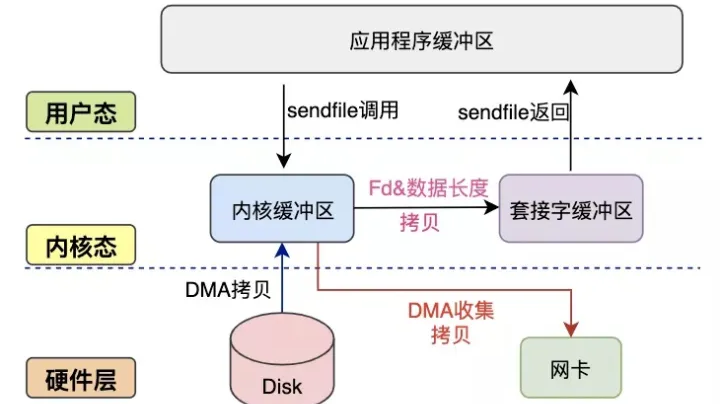
- Linux 内核2.4版本优化了
优点:
- 由于描述性信息数据量非常小,可以认为消除了CPU拷贝
缺点:
- 仍无法修改数据,且需硬件DMA的配合
- 只能将文件数据拷贝到socket描述符,存在局限性
splice#
实现方式:
splice系统调用由Linux内核2.6版本引入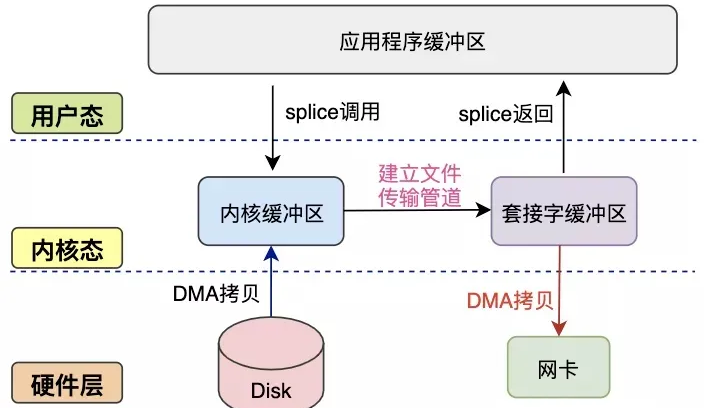
优点:
- splice 在内核的不同缓冲区之间采用管道传输数据,避免 CPU 拷贝
- 无需硬件支持
- 不局限于socket,可实现普通文件 (文件描述符) 间的数据零拷贝
缺点:
- 文件描述符中至少有一个是管道(
pipe)
- 文件描述符中至少有一个是管道(
零拷贝实践#
- Kafka:调用 Java NIO 库里的 transferTo 方法,如 Linux 系统支持 sendfile(),transferTo() 最终将使用 sendfile() 系统调用函数
- Nginx:使用 sendfile()
函数指针#
定义
- 函数指针指向的是特殊的数据类型,函数的类型是由其返回的数据类型和其参数列表共同决定的,而函数的名称则不是其类型的一部分
- 一个具体函数的名字,如果后面不跟调用符号(即括号),则该名字就是该函数的指针(注:大部分情况下正确,但并不严格)
声明方法
int (*pf)(const int&, const int&);上面的pf就是一个函数指针,指向所有返回类型为int,并带有两个const int&参数的函数。注意*pf两边的括号是必须的,否则上面的定义就变成了:
int *pf(const int&, const int&);而这声明了一个函数pf,其返回类型为int *, 带有两个const int&参数。
为什么有函数指针
- 函数与数据项相似,函数也有地址。在同一个函数中通过使用相同的形参在不同的时间使用产生不同的效果。
- 一个函数名就是一个指针,它指向函数的代码。一个函数地址是该函数的进入点,也就是调用函数的地址。函数的调用可以通过函数名,也可以通过指向函数的指针来调用。函数指针还允许将函数作为变元传递给其他函数;
- 两种方法赋值: 指针名 = 函数名; 指针名 = &函数名