- cpp/
1. C++语法
Table of Contents
头文件#
- 头文件通常以
.h或.hpp为后缀名 - 尖括号
#include <...>: 编译器认定为标准的或项目专属的头文件,搜索时会优先在某些默认目录(一般为系统路径)寻找 - 双引号
#include "...": 编译器认为是用户提供的头文件,搜索时会在头文件所在的目录内寻找
宏#
宏定义可以实现类似于函数的功能,但是它终归不是函数,而宏定义中括弧中的“参数”也不是真的参数,在宏展开的时候对 “参数” 进行的是一对一的替换。
使用宏时要非常谨慎,尽量以内联函数、枚举和常量代替
#:对应变量字符串化#define mkstr(s) #s mkstr(lervisnh); // 输出 lervisnh连接符
#@:将单字符标记符变换为单字符,即加单引号#define B(x) #@x // B(a)即'a',B(1)即'1'##:把宏参数名与宏定义代码序列中的标识符连接在一起,形成一个新的标识符#define concat(a, b) a##b int xy = 101; printf("%d", concat(x, y)); // 输出101
auto#
- C++11 之前,用来声明自动变量,表明变量存储在栈,很少使用
- 自动类型推断 (C++11)
auto i = 42; //i is an int
auto l = 42LL; //l is an long long
auto p = new foo(); //p is a foo*
函数返回值的占位符 (C++11)
声明或定义函数返回值的占位符,需与
decltype配合使用如果函数有一个尾随的返回类型时,
auto可以出现在函数声明中返回值位置。此时,auto 是指引编译器去函数的末端寻找返回值类型。如下例,函数返回值类型是 operator+ 操作符作用在 T、U 类型变量上的返回值类型template<class T, class U> auto add(T t, U u) -> decltype(t + u) { return t + u; }
const#
作用:
- 修饰变量,说明该变量不可以被改变
- 修饰指针,分为指向常量的指针和指针常量
- 常量引用,常用于形参类型,既避免了拷贝,又避免了函数对值的修改
- 修饰成员函数,承诺成员函数内不能修改成员变量(作为函数签名的一部分)
const在类中的使用:当成员函数的
const和non-const版本同时存在,const object只会(只能)调用const版本,non-const object只会(只能)调用non-const版本常量对象和常量成员函数:
const member function保证不改变 data membernon-const member function可能会改变 data memberconst object不能改变data member可以使用 不能使用 non-const objectdata member可变动可以使用 可以使用
使用:
- 类
class A {
private:
const int a; // 常对象成员,只能在初始化列表赋值
public:
A() : a(0) { }; // 构造函数
A(int x) : a(x) { }; // 初始化列表
// const可用于对重载函数的区分
int getValue(); // 普通成员函数
int getValue() const; // 常成员函数, 不得修改类中的任何数据成员的值
// 编译时const会被包含进函数签名
};
- 对象(实例化的类)
void function() {
A b; // 普通对象,可以调用全部成员函数、更新常成员变量
const A a; // 常对象,只能调用常成员函数
const A *p = &a; // 常指针
const A &q = a; // 常引用
// 指针
char greeting[] = "Hello";
char* p1 = greeting; // 指针变量,指向字符数组变量
const char* p2 = greeting; // 指针变量,指向字符数组常量
char* const p3 = greeting; // 常指针,指向字符数组变量
const char* const p4 = greeting; // 常指针,指向字符数组常量
}
- 函数
void function1(const int Var); // 传递过来的参数在函数内不可变
void function2(const char* Var); // 参数指针所指内容为常量
void function3(char* const Var); // 参数指针为常指针
void function4(const int& Var); // 引用参数在函数内为常量
- 函数返回值
const int function5(); // 返回一个常数
const int* function6(); /* 返回一个指向常量的指针变量
使用:const int *p = function6(); */
int* const function7(); /* 返回一个指向变量的常指针
使用:int* const p = function7(); */
- 函数后置const
class ClassName{
public:
int Fun() const;
/* 函数后置const, 后置的形式是一种规定,为了不引起混淆;
此函数的声明和定义均要使用const, 因为const已经成为类型信息(函数签名)的一部分
获得能力:可以操作常量对象
失去能力:不能修改类的数据成员,不能在函数中调用其他不是const的函数
*/
}
constexpr (C++11)#
常量表达式函数
函数返回值在编译时期可确定,使用constexpr修饰函数返回值,使函数成为常量表达式函数;且满足:
a. 函数必须有返回值
b. 函数体只有单一的return语句
c. return语句中的表达式也必须是一个常量表达式
d. 函数在使用前必须已有定义
constexpr int f(){return 1;}
常量表达式值
认定变量是一个常量表达式,那就把它声明为constexpr类型
constexpr int i=3; //i是一个常变量 constexpr int j=i+1; //i+1是一个常变量 constexpr int k=f(); //只有f()是一个constexpr函数时,k才是一个常量表达式 // constexpr声明定义了一个指针, 仅对指针有效, 与指针所指对象无关 const int *p=nullptr; //p是一个指向整型常量的指针(pointer to const) constexpr int *p1=nullptr; //p1是一个常量指针(const pointer)
常量表达式作用于函数模板
struct NotConstType { int i; NotConstType(int x) :i(x) {} }; NotConstType myType; //constexpr作用于函数模板 template <typename T> constexpr T ConstExpFunc(T t) { return t; } int main() { NotConstType objTmp = ConstExpFunc(myType);//编译通过,ConstExpFunc实例化为普通函数,constexpr被忽略 constexpr NotConstType objTmp1 = ConstExpFunc(myType);//编译失败 constexpr int a = ConstExpFunc(1);//编译通过,ConstExpFunc实例化为常量表达式函数 }constexpr元编程- 作用于递归函数来实现编译期的数值计算;C++11标准规定,常量表达式应至少支持512层递归。
constexpr int Fibonacci(int n) { return (n == 1) ? 1 : (n == 2 ? 1 : Fibonacci(n - 1) + Fibonacci(n - 2)); }; int main() { constexpr int fib8 = Fibonacci(8); //编译期常量等于21 }
constexpr VS const#
const可修饰函数参数、函数返回值、函数本身、类等,描述的是“运行时常量性”,即在运行时数据具有不可更改性constexpr可修饰函数参数、函数返回值、变量、类的构造函数、函数模板等,比const的约束更加严格,除具有“运行时常量性”,也具有“编译时常量性”,即编译期可知constexpr修饰的表达式的值
const int getConst(){ return 1; }
enum{ e1=getConst(),e2}; //编译出错
//换成constexpr即可在编译期确定函数返回值用于初始化enum常量
constexpr int getConst(){ return 1; }
enum{ e1=getConst(),e2}; //编译OK
mutable#
- 为了突破
const的限制而设置的 - 被 mutable 修饰的变量,将永远处于可变的状态,即使在一个
const函数中,甚至结构体变量或者类对象为const,其 mutable 成员也可以被修改 - mutable 在类中只能够修饰非静态数据成员
- mutable 数据成员的使用看上去像是骗术,因为它能够使
const函数修改对象的数据成员。mutable 能够向用户隐藏实现细节,而无须使用不确定的东西 - 如果类的成员函数不会改变对象的状态,该成员函数一般被声明成
const;但是,如果需要在const的函数中修改一些跟类状态无关的数据成员,该使用mutalbe修饰数据成员 mutable的意义:对mutable声明的变量所做的改变不会破坏class object的常量性,不能视为改变class object的状态
struct tagData {
int a;
mutable int b;
};
class clsData {
public:
int a;
mutable int b;
void show() const {
a = 2;//错误,不能在const成员函数中修改普通变量
b = 5;//正确
printf("a: %d, b: %d\r\n");
}
};
int _tmain(int argc, _TCHAR* argv[]) {
//结构体变量为const,其mutable成员也可以被修改
const tagData dat = {0, 0};
dat.a = 8;//编译错误
dat.b = 9;//编译通过
//类对象为const,其mutable成员也可以被修改
clsData cls;
cls.show();
return 0;
}
restrict#
- C99标准引入
- 用于限定和约束指针,并表明指针是访问一个数据对象的唯一且初始的方式
- 它告诉编译器,所有修改该指针所指向内存中内容的操作都必须通过该指针来修改,而不能通过其它途径(其它变量或指针)来修改
- 好处:帮助编译器进行更好的优化代码,生成更有效率的汇编代码
int *restrict ptr
/* ptr 指向的内存单元只能被 ptr 访问到,
任何同样指向这个内存单元的其他指针都是未定义的(即无效指针/野指针) */
static#
作用:
- 修饰普通变量,修改变量的存储区域和生命周期,使变量存储在静态区,在 main 函数运行前就分配了空间,如果有初始值就用初始值初始化它,如果没有初始值系统用默认值初始化它。
- 修饰普通函数,表明函数的作用范围,仅在定义该函数的文件内才能使用。在多人开发项目时,为了防止与他人命名空间里的函数重名,可以将函数定位为 static。
- 修饰成员变量,修饰成员变量使所有的对象只保存一个该变量,而且不需要生成对象就可以访问该成员。表示唯一的、可共享的成员变量。
- 修饰成员函数,修饰成员函数使得不需要生成对象就可以访问该函数,但是在 static 函数内不能访问非静态成员。
静态变量什么时候初始化#
- 初始化只有一次,但可以多次赋值,在主程序之前,编译器已经为其分配好了内存
- 静态局部变量和全局变量一样,数据都存放在全局区域,所以在主程序之前,编译器已经为其分配好了内存
- 在C中,初始化发生在代码执行之前,编译阶段分配好内存,就会进行初始化,所以C语言无法使用变量对静态局部变量进行初始化,在程序运行结束,变量所处的全局内存会被全部回收。
- 而在C++中,初始化时在执行相关代码时才会进行初始化,全局变量、文件域的静态变量和类的静态成员变量在main执行之前的静态初始化过程中分配内存并初始化;局部静态变量(一般为函数内的静态变量)在第一次使用时(运行到声明处)分配内存并初始化。这里的变量包含内置数据类型和自定义类型的对象。
指针#
指针的本意是内存地址,可以通俗理解为内存编号;通过编号来操作内存单元,造就了指针的高效率
使用:
int *ip; /* 一个整型的指针 */ double *dp; /* 一个 double 型的指针 */ float *fp; /* 一个浮点型的指针 */ char *ch; /* 一个字符型的指针 */
nullptr_t / nullptr (C++11)#
C++11 之前,用 0 来表示空指针,但由于 0 会被隐式类型转换为整型,某些场景下会存在问题
nullptr 是 std::nullptr_t 类型的值,用来指代空指针常量
nullptr 和任何指针类型、类成员指针类型的空值可发生隐式类型转换,也可隐式转换为 bool 型 (取值为false)
nullptr 不存在到整型的隐式转换
int* p1 = NULL; int* p2 = nullptr;使用注意:
- 可以使用 nullptr_t 定义空指针,但所有定义为 nullptr_t 类型的对象行为上是完全一致的
- nullptr_t 类型对象可以隐式转换为任意一个指针类型
- nullptr_t 类型对象不能转换为非指针类型,即使
reinterpret_cast强制类型转换也不行 - nullptr_t 类型对象不能用于算术运算表达式
- nullptr_t 类型对象可以用于关系运算表达式,但仅能与 nullptr_t 类型或指针类型对象比较,当且仅当关系运算符为==、>=、<=时,如果相等则返回 true
引用#
引用在语法上是值变量却拥有指针的语义
所有按引用传递的参数必须加上
const- 输入参数是值参或
const引用, 输出参数为指针 - 输入参数可以是
const指针, 但决不能是非const的引用参数,除非用于交换,如swap()
- 输入参数是值参或
以下情况输入形参中用
const T*指针- 会传 null 指针
- 函数把指针或对地址的引用赋值给输入形参
左值与左值引用#
左值
lvalue:永久对象,可被取地址,可以出现在operator=左侧。如:有名称的变量、函数形参(栈中的对象)等。函数形参都是左值,因为函数形参都有名称,都可以对形参进行取地址操作
左值引用:常规引用,一般表示对象的身份。通过在类型名后加
&来表示。
右值与右值引用#
- 右值
rvalue:临时对象(即将销毁),不可取地址,只能出现在operator=右侧(标准库中有例外,如string、complex 等)。典型的rvalue:字面常量(如1、2…等)、匿名对象(临时对象)以及函数的返回值等。另外,也可以通过std::move显式地将一个左值转换为右值。 - 右值引用只能绑定到临时对象的引用
- 一个表达式的值要么是 lvalue,要么是 rvalue。
- 右值引用和左值引用都是引用,都是一个变量(即都是一个左值),右值引用则通过在类型名后加
&&表示。只不过左值引用引用的是左值,而右值引用只能引用右值。 - 在C++11之前为了能够将右值(或临时对象)作为引用参数传递给函数,C++标准故意设置了这一个特例:将函数参数声明为
const Type &即可(其中 Type为具体类型)。 - 不能将一个右值绑定到一个非常量左值引用上
- 只在定义移动构造函数与移动赋值操作时使用右值引用;不要使用
std::forward - 右值引用可实现转移语义(Move Sementics)和精确传递(Perfect Forwarding),主要目的有:
- 消除两个对象交互时不必要的对象拷贝,节省运算存储资源,提高效率。
- 能够更简洁明确地定义泛型函数。
引用折叠/引用坍缩#
X& &、X& &&、X&& &可折叠成X&X&& &&可折叠成X&&
完美转发#
std::forward 被称为完美转发,它的作用是保持原来的值属性不变
- 如果原来的值是左值,经std::forward处理后该值还是左值
- 如果原来的值是右值,经std::forward处理后它还是右值
引用的使用#
- 把引用作为参数:通过使用引用来替代指针,使 C++ 程序更容易阅读和维护。C++ 函数可返回一个引用,方式与返回一个指针类似。当函数返回一个引用时,则返回一个指向返回值的隐式指针。这样,函数就可以放在赋值语句的左边。 参考
- 把引用作为返回值:从 C++ 函数中返回引用,就像返回其他数据类型一样。 参考
指针 VS 引用#
- 相同点:都是内存地址的概念
- 不同点:
引用Reference 指针Pointer 初始化 必须被初始化,但不分配存储空间 不声明时初始化,初始化时需分配存储空间 重新分配 初始化后不能被改变 能够改变所指的地址 内存地址 与原始变量共享相同的地址,是内存空间的别名 存储变量的地址 参数使用 引用传递 值传递 符号表的体现 符号表对应地址值为引用对象的地址值,且生成后不再改变 符号表对应地址值为指针变量的地址值
前/后置++#
i++#
- 将i值取出放到寄存器
- 将寄存器中的值返回
- 寄存器中的值加1
- 使用寄存器值修改i的值
++i#
- 将i值取出放到寄存器
- 寄存器中的值加1
- 将寄存器中的值返回并修改i的值
迭代器 ++it#
- 前置返回一个引用,不会产生临时对象
int& operator++() {
*this += 1;
return *this;
}
迭代器 it++#
- 后置返回一个对象,必须产生临时对象,临时对象会导致效率降低
int operator++(int) {
int temp = *this;
++*this;
return temp;
}
inline 内联函数#
- 必须将
inline函数放在头文件 - inline 内联函数:将函数体直接插入调用处
- 特征:
- 相当于把内联函数里面的内容写在调用内联函数处;
- 相当于不用执行进入函数的步骤,直接执行函数体;
- 相当于宏,却比宏多了类型检查,真正具有函数特性;
- 编译器一般不内联包含循环、递归、switch 等复杂操作的内联函数;
- 在类声明中定义的函数,除了虚函数的其他函数都会自动隐式地当成内联函数。
- 使用:
// 声明1(加 inline,建议使用)
inline int functionName(int first, int second,...);
// 声明2(不加 inline)
int functionName(int first, int second,...);
// 定义
inline int functionName(int first, int second,...) {/****/};
// 类内定义,隐式内联
class A {
int doA() { return 0; } // 隐式内联
}
// 类外定义,需要显式内联
class A {
int doA();
}
inline int A::doA() { return 0; } // 需要显式内联
- 编译器对 inline 函数的处理步骤:
- 将 inline 函数体复制到 inline 函数调用点处;
- 为所用 inline 函数中的局部变量分配内存空间;
- 将 inline 函数的的输入参数和返回值映射到调用方法的局部变量空间中;
- 如果 inline 函数有多个返回点,将其转变为 inline 函数代码块末尾的分支(使用 GOTO)。
- 优点:
- 内联函数同宏函数一样将在被调用处进行代码展开,省去了参数压栈、栈帧开辟与回收,结果返回等,从而提高程序运行速度。
- 内联函数相比宏函数来说,在代码展开时,会做安全检查或自动类型转换(同普通函数),而宏定义则不会。
- 在类中声明同时定义的成员函数,自动转化为内联函数,因此内联函数可以访问类的成员变量,宏定义则不能。
- 内联函数在运行时可调试,而宏定义不可以。
- 缺点:
- 代码膨胀。内联是以代码膨胀(复制)为代价,消除函数调用带来的开销。如果执行函数体内代码的时间,相比于函数调用的开销较大,那么效率的收获会很少。另一方面,每一处内联函数的调用都要复制代码,将使程序的总代码量增大,消耗更多的内存空间。
- inline 函数无法随着函数库升级而升级。inline函数的改变需要重新编译,不像 non-inline 可以直接链接。
- 是否内联,程序员不可控。内联函数只是对编译器的建议,是否对函数内联,决定权在于编译器。
volatile#
- volatile 是一种类型修饰符,用它声明的类型变量可以避免被某些编译器未知的因素(操作系统、硬件、其它线程等)更改,即编译器不会被
volatile修饰的变量/对象进行优化 - volatile 声明的变量,每次访问时都必须从内存中取出值(如没有被 volatile 修饰的变量,可能由于编译器优化,从 CPU 寄存器中取值)
const可以是 volatile (如只读的状态寄存器)- 指针可以是 volatile
assert()#
- 断言,是宏,而非函数
- assert 宏的原型定义在
<assert.h>(C)、<cassert>(C++),其作用是如果它的条件返回错误,则终止程序执行 - 可通过在定义
#include <assert.h>之前NDEBUG来关闭 assert - 使用
#define NDEBUG // 加上这行,则 assert 不可用
#include <assert.h>
assert( p != NULL ); // assert 不可用
static_assert (C++11)#
C++11引入的静态断言,用于检测和诊断编译期错误(assert用于运行时断言宏)
断言表达式必须是在编译期可以计算的表达式,即必须是常量表达式。如果为 true 可正常编译;如果断言表达式的值为 false ,编译器会出现一个包含指定字符串的错误,导致编译失败。如
static_assert(sizeof(void*) == 8,"not supported");编译时提供关于类型的信息,但需和
type traits配合使用。头文件<type_traits>中的helper class,用来产生编译时常量;type traits class,用来在编译时获取类型信息;type transformation class 可以将已存在的类型变换为新的类型。如template <typename T1, typename T2> auto add(T1 t1, T2 t2) { static_assert(std::is_integral<T1>::value, "Type T1 must be integral"); static_assert(std::is_integral<T2>::value, "Type T2 must be integral"); return t1 + t2; }; std::cout << add(1, 3.14) << std::endl; // 编译报错 std::cout << add("one", 2) << std::endl; // 编译报错注意事项:
- static_assert可用在全局作用域、命名空间、类作用域、函数作用域,几乎不受限制
- static_assert能够在编译期间发现更多的错误,用编译器来强制保证一些契约,改善编译信息的可读性,尤其用于模板
- 编译器对static_assert语句会立刻将其第一个参数作为常量表达式进行演算;如第一个常量表达式依赖于某些模板参数,则延迟到模板实例化时再进行演算,因此能够检查模板参数
- 由于static_assert编译期间断言,不生成目标代码,所以不会造成任何运行期性能损失
sizeof()#
- 单目运算符,不是函数;sizeof 不能用来返回动态分配的内存空间的大小
- sizeof 对数组,得到整个数组所占空间大小
- sizeof 对指针,得到指针本身所占空间大小
sizeof… (C++11)#
获取 C++11 中可变参数模板中参数包中元素个数,
sizeof…返回一个常量表达式,而且不会对模板的实参求值template<typename... Args> void g(Args... args) { cout << sizeof...(Args) << endl; //类型参数的数目 cout << sizeof...(args) << endl; //函数参数的数目 }
strlen#
size_t strlen(char const* str);
- 是一个函数,所以需要进行一次函数调用
- 用来计算指定字符串
str的长度,但不包括结束字符(即 null 字符)
strcpy / strncpy / strcat / strcmp#
strcpy: 复制字符串,a中字符串复制到b中,b中的字符串将被覆盖。strcat: 字符串的连接,没有覆盖现象strncpy: 复制字符串的前n个字符,如果是复制所有的字符会包含’\0’,但是中间的话就没有,要自己添加,例如:strncpy(b,a,i-1); b[i-1]='\0';strcmp:对两个字符串进行比较,然后返回比较结果- 函数形式如下:
int strcmp(const char*str1,const char*str2); 其中str1和str2可以是字符串常量或者字符串变量,返回值为整形。返回结果如下规定: ① str1小于str2,返回负值或者-1(VC返回-1) ② str1等于str2,返回0 ③ str1大于str2,返回正值或者1(VC返回1)
- 实现原理:对字符的ASCII码进行比较。首先比较两个串的第一个字符,若不相等,则停止比较并得出两个ASCII码大小比较的结果;如果相等就接着比较第二个字符然后第三个字符等等。无论两个字符串是什么样,strcmp函数最多比较到其中一个字符串遇到结束符’/0’为止,就能得出结果。
手动实现string类#
#include <cstring>
#include <iostream>
using namespace std;
class Mystring {
char* str;
public:
Mystring() : str{ nullptr } {
str = new char[1];
str[0] = '\0';
};
Mystring(char* val) {
if (val == nullptr) {
str = new char[1];
str[0] = '\0';
}
else {
str = new char[strlen(val) + 1];
// Copy character of val[]
// using strcpy
strcpy(str, val);
str[strlen(val)] = '\0';
cout << "The string passed is: "
<< str << endl;
}
};
// Copy Constructor
Mystring(const Mystring& source) {
str = new char[strlen(source.str) + 1];
strcpy(str, source.str);
str[strlen(source.str)] = '\0';
};
// Move Constructor
Mystring(Mystring&& source) {
str = source.str;
source.str = nullptr;
};
// Destructor
~Mystring() { delete str; }
};
int main() {
Mystring a;
char temp[] = "Hello";
Mystring b{ temp };
Mystring c{ a }; // copy constructor
char temp1[] = "World";
Mystring d{ Mystring{ temp } }; // move constructor
return 0;
};
重载运算符#
- 只能重载已有的运算符,而无权发明新的运算符;对于一个重载的运算符,其优先级和结合律与内置类型一致才可以;不能改变运算符操作数个数
.::?:sizeoftypeid**不能重载- 两种重载方式,成员运算符和非成员运算符,成员运算符比非成员运算符少一个参数;下标运算符、箭头运算符必须是成员运算符;
- 引入运算符重载,是为了实现类的多态性
- 当重载的运算符是成员函数时,this绑定到左侧运算符对象。成员运算符函数的参数数量比运算符对象的数量少一个;至少含有一个类类型的参数
- 从参数的个数推断到底定义的是哪种运算符,当运算符既是一元运算符又是二元运算符(
+,-,*,&) - 下标运算符必须是成员函数,下标运算符通常以所访问元素的引用作为返回值,同时最好定义下标运算符的常量版本和非常量版本;箭头运算符必须是类的成员,解引用通常也是类的成员;重载的箭头运算符必须返回类的指针
函数调用与返回#
当调用一个函数时,系统发生进行如下动作,内存模型如下图:
- 开辟该调用函数的栈空间
- 将当前的运行状态压栈(从右向左依次把被调函数所需要的参数压入栈)
- 将返回地址压栈
- 在栈内为传参分配空间
- 在栈内为函数内局部变量分配空间,执行被调用函数
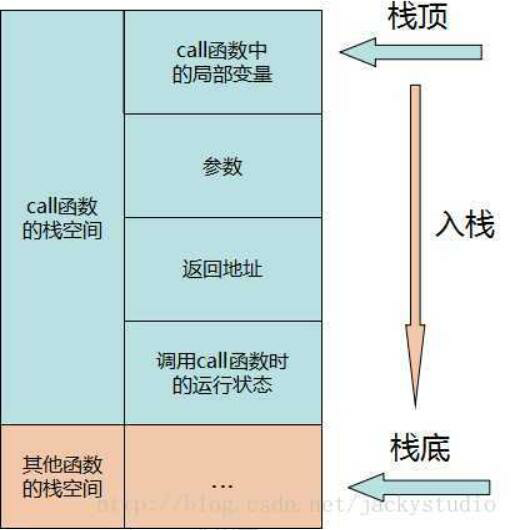
当返回函数时,系统进行的动作刚好与函数调用时相反,内存模型如下图:
释放栈内局部变量空间
释放栈内传参空间
退栈,得到返回地址,程序跳转调用处等待
退栈,得到调用前运行状态,恢复调用前运行状态
释放该调用函数栈空间
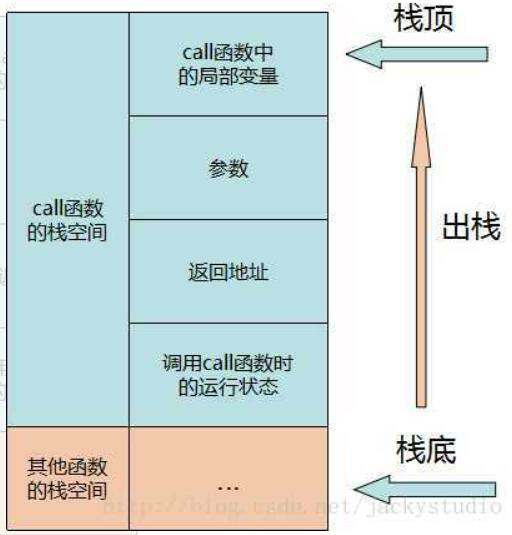
- 局部变量在函数调用结束后就被销毁。栈是内存中的一部分空间,因此也是有限资源,如频繁调用函数而不返回已调用函数,栈就会被不断开辟,最终导致栈溢出(stack overflow),程序崩溃,所以在处理一些递归函数上需要特别注意结束条件
函数调用约定:
- 传递参数,即参数从右自左压入堆栈,函数内部正好从左自右读出参数
- 函数执行清除堆栈,即调用函数是堆栈中压入参数时占用了位置,这些位置由调用函数负责清空
__stdcall 和 __cdecl 的区别#
__stdcall:恢复函数自身的堆栈,只有在函数代码的结尾出现一次恢复堆栈的代码;编译时就规定了参数个数,无法实现不定个数的参数调用__cdecl:恢复堆栈,假设有100个函数调用函数a,那么内存中就有100端恢复堆栈的代码;可以不定参数个数;每一个调用它的函数都包含清空堆栈的代码,所以产生的可执行文件大小会比调用__stacall函数大。支持可变参数,如fprintf()
c++符号表解析/函数签名#
- 函数签名:包含了一个函数的信息,包括函数名、它的参数类型、它所在的类和名称空间及其他信息
- 函数签名用于识别不同的函数
- 函数签名顺序:命名空间(如有) –> 类名(如有) –> 函数名
命名空间与作用域#
namespace#
命名冲突/命名空间污染:定义的变量、函数、类等和不同库中的内容发生冲突,如下:
#include <stdio.h> #include <stdlib.h> // 定义了 rand() 的函数 int rand = 0; // 与 rand() 名称冲突 int main(void) { printf("rand = %d\n", rand); return 0; }namespace: 避免与其他库定义的名字冲突,将库的内容放置在自己独立的命名空间中;如C++标准库的命名空间为
std#include <stdio.h> #include <stdlib.h> // 定义了 rand() 的函数 namespace r { int rand = 0; }; int main(void) { printf("rand = %d\n", rand); // rand() 函数地址 printf("rand = %d\n", rand()); // rand() 函数返回值 printf("rand = %d\n", r::rand); // 0, 上边定义的数值 return 0; }
using (C++11)#
using 声明:一次只引入命名空间的一个成员,可以清楚知道程序中所引用的到底是哪个名字。如:
using namespace_name::name;构造函数的 using 声明:派生类能够重用它的直接基类定义的构造函数
class Derived : Base { public: using Base::Base; /* ... */ };如上 using 声明,对于基类的每个构造函数,编译器都生成一个与之对应(形参列表完全相同)的派生类构造函数。生成如下类型构造函数:
Derived(parms) : Base(args) { }using 指示:使得某个特定命名空间中所有名字都可见,无需再添加任何前缀限定符。如:
using namespace_name name;using 使用注意事项
少使用
using 指示:使用 using 命令比使用 using 编译命令更安全,是因为只导入了指定的名称。如果该名称与局部名称发生冲突,编译器将发出指示。using编译命令导入所有的名称,包括可能并不需要的名称。如果与局部名称发生冲突,则局部名称将覆盖名称空间版本,而编译器并不会发出警告。另外,名称空间的开放性意味着名称空间的名称可能分散在多个地方,导致难以准确知道添加了哪些名称。using namespace std;多使用
using 声明int x; std::cin >> x ; std::cout << x << std::endl; // 或者 using std::cin; using std::cout; using std::endl; int x; cin >> x; cout << x << endl;
:: 范围解析运算符#
全局作用域符(
::name):用于类型名称(类、类成员、成员函数、变量等)前,表示作用域为全局命名空间类作用域符(
class::name):用于表示指定类型的作用域范围是具体某个类的命名空间作用域符(
namespace::name):用于表示指定类型的作用域范围是具体某个命名空间的::使用int count = 11; // 全局(::)的 count class A { public: static int count; // 类 A 的 count(A::count) }; int A::count = 21; void fun() { int count = 31; // 初始化局部的 count 为 31 count = 32; // 设置局部的 count 的值为 32 } int main() { ::count = 12; // 测试 1:设置全局的 count 的值为 12 A::count = 22; // 测试 2:设置类 A 的 count 为 22 fun(); // 测试 3 return 0; }
enum 枚举类型#
限定作用域的枚举类型#
enum class open_modes { input, output, append };
不限定作用域的枚举类型#
enum color { red, yellow, green };
enum { floatPrec = 6, doublePrec = 10 };
decltype (C++11)#
- 从表达式的类型推断出要定义的变量类型,但是不想用该表达式的值初始化变量(初始化可以用
auto)。为了满足这一需求,C++11新标准引入了decltype类型说明符,它的作用是选择并返回操作数的数据类型,在此过程中,编译器分析表达式并得到它的类型,却不实际计算表达式的值 decltype关键字用于检查实体的声明类型或表达式的类型及值分类。语法:
decltype ( expression )
decltype使用
// 尾置返回允许我们在参数列表之后声明返回类型
template <typename It>
auto fcn(It beg, It end) -> decltype(*beg)
{
// 处理序列
return *beg; // 返回序列中一个元素的引用
}
// 为了使用模板参数成员,必须用 typename
template <typename It>
auto fcn2(It beg, It end) -> typename remove_reference<decltype(*beg)>::type
{
// 处理序列
return *beg; // 返回序列中一个元素的拷贝
}
位域#
Bit mode: 2; // mode 占 2 位
类可以将其(非静态)数据成员定义为位域(bit-field),在一个位域中含有一定数量的二进制位。当一个程序需要向其他程序或硬件设备传递二进制数据时,通常会用到位域。
- 位域在内存中的布局是与机器有关的
- 位域的类型必须是整型或枚举类型,带符号类型中的位域的行为将因具体实现而定
- 取地址运算符(&)不能作用于位域,任何指针都无法指向类的位域
extern 和 extern “C”#
- extern 表示变量或者函数的定义在别的文件中。提示编译器遇到此变量或函数时,在其它模块中寻找其定义,另外,extern也可用来进行链接指定
- 被 extern 限定的函数或变量是 extern 类型的
- 被
extern "C"修饰的变量和函数是按照 C 语言方式编译和链接的 - 作用:让 C++ 编译器将
extern "C"声明的代码当作 C 语言代码处理,避免因符号修饰导致不能和C语言库的符号链接的问题 - 使用
#ifdef __cplusplus
extern "C" {
#endif
void *memset(void *, int, size_t);
#ifdef __cplusplus
}
#endif
struct 和 typedef struct#
C 中#
// c
typedef struct Student {
int age;
} S;
等价于
// c
struct Student {
int age;
};
typedef struct Student S;
此时 S 等价于 struct Student,但两个标识符名称空间不相同。
另外还可以定义与 struct Student 不冲突的 void Student() {}。
C++ 中#
由于编译器定位符号的规则(搜索规则)改变,导致不同于C语言。
- 如果在类标识符空间定义了
struct Student {...};,使用Student me;时,编译器将搜索全局标识符表,Student未找到,则在类标识符内搜索。即表现为可以使用Student也可以使用struct Student,如下:
// cpp
struct Student {
int age;
};
void f( Student me ); // 正确,"struct" 关键字可省略
- 若定义了与
Student同名函数之后,则Student只代表函数,不代表结构体,如下:
typedef struct Student {
int age;
} S;
void Student() {} // 正确,定义后 "Student" 只代表此函数
//void S() {} // 错误,符号 "S" 已经被定义为一个 "struct Student" 的别名
int main() {
Student();
struct Student me; // 或者 "S me";
return 0;
}
C++ 中 struct 和 class#
struct 是一个数据结构的实现体,class 是一个对象的实现体。
struct 和 class的区别#
- 最本质的区别就是默认的访问控制
- 默认的继承访问权限。struct 是 public ,class 是 private
- struct 作为数据结构的实现体,默认的数据访问控制是 public
- class 作为对象的实现体,默认的成员变量访问控制是 private
union 联合#
联合(union)是一种节省空间的特殊的类,一个 union 可以有多个数据成员,但是在任意时刻只有一个数据成员可以有值。当某个成员被赋值后其他成员变为未定义状态。联合有如下特点:
- 默认访问控制符为 public
- 可以含有构造函数、析构函数
- 不能含有引用类型的成员
- 不能继承自其他类,不能作为基类
- 不能含有虚函数
- 匿名 union 在定义所在作用域可直接访问 union 成员
- 匿名 union 不能包含 protected 成员或 private 成员
- 全局匿名联合必须是静态(static)的
- 使用:
#include <iostream>
using std::cout;
using std::endl;
union UnionTest {
UnionTest() : i(10) {};
int i;
double d;
};
static union {
int i;
double d;
};
int main() {
UnionTest u;
union {
int i;
double d;
};
cout << u.i << endl; // UnionTest 联合的 10
::i = 20;
cout << ::i << endl; // 全局静态匿名联合的 20
i = 30;
cout << i << endl; // 局部匿名联合的 30
return 0;
}
异常处理#
异常:某种对象,大部分时候被抛出的异常属于特定的异常类;异常包括了 异常的鉴定与发出 和 异常的处理方式
C++规定每个异常都应该被处理,直至调用标准库的
terminate()中断整个程序的执行在异常处理机制终结某个函数之前,C++保证函数中的所有局部对象的析构函数都会被调用(涉及局部资源管理)
extern Mutex m; void f() { int *p = new int; m.acquire(); process(p); // 抛出异常导致后续代码不能执行, 造成资源泄漏 m.release(); delete p; }所有
catch子句成功运行后,即不抛出其他异常,由正常程序接手重新抛出:
catch(iterrator_overflow &iof) { log_message(iof.what_happenned()); throw; // 重新抛出异常 }捕获任何类型异常:
catch(.../*捕获任意异常*/) { log_message("exception of unknown type"); // 其他操作 }
noexcept (C++11)#
修饰符
voidFunc3() noexcept; voidFunc4() noexcept(常量表达式);voidFunc3()表示函数不会抛出异常,noexcept修饰的函数抛出了异常,编译器调用std::terminate()终止程序运行voidFunc4()常量表达式的结果为true,表示该函数不会抛出异常,反之(false)则有可能抛出异常
操作符(常用于模板)
template <typename T> void func5() noexcept(noexcept(T())) {}noexcept(T())是一个操作符,如果其参数是一个有可能抛出异常的表达式,noexcept(T())则返回值为false,那么 func5 有可能会抛出异常;如果noexcept(T())返回 true,func5 不会抛出异常- 函数模板是否会抛出异常,可由表达式进行推导,使得 C++11 更好支持泛型